- 博客/
高可用prometheus监控集群搭建(四)
·670 字·4 分钟
kubernetes
prometheus
高可用prometheus监控集群部署 - This article is part of a series.
Part 4: This Article
Prometheus可以定义警报规则,满足条件时触发警报,并推送到Alertmanager服务。Alertmanager支持高可用的集群部署,负责管理、整合和分发警报到不通目的地,并能做到告警收敛 本例采用statefulset方式部署3个实例的Alertmanager高可用集群
Alertmanager集群部署#
创建alertmanager数据目录#
$ mkdir /data/alertmanager
创建storageclass#
$ cat storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: alertmanager-lpv
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
创建local volume#
$ cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: alertmanager-pv-0
spec:
capacity:
storage: 30Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: alertmanager-lpv
local:
path: /data/alertmanager
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- 192.168.1.50
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: alertmanager-pv-1
spec:
capacity:
storage: 30Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: alertmanager-lpv
local:
path: /data/alertmanager
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- 192.168.1.51
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: alertmanager-pv-2
spec:
capacity:
storage: 30Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: alertmanager-lpv
local:
path: /data/alertmanager
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- 192.168.1.52
创建alertmanager.yml的configmap#
通过Alertmanager提供的webhook支持,可以配置钉钉告警。需要定义基于webhook的告警接收器receiver。alertmanager.yml文件定义告警方式、模板、告警的分发策略和告警抑制策略等
#cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 3m #解析的超时时间
route:
group_by: ['example']
group_wait: 60s
group_interval: 60s
repeat_interval: 12h
receiver: 'DingDing'
receivers:
#定义基于webhook的告警接收器receiver
- name: 'DingDing'
webhook_configs:
- url: http://192.168.1.50:8060/dingtalk/webhook/send
send_resolved: true # 发送已解决通知
部署prometheus-webhook-dingtalk#
这里使用docker部署
$ docker pull timonwong/prometheus-webhook-dingtalk
$ docker run -d -p 8060:8060 --name webhook timonwong/prometheus-webhook --ding.profile="webhook=https://oapi.dingtalk.com/robot/send?access_token={自己的dingding token}
钉钉群添加自定义机器人,可以生成Webhook地址https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxx
创建headless service#
$ cat service-statefulset.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
spec:
ports:
- name: altermanager
port: 9093
targetPort: 9093
selector:
k8s-app: alertmanager
clusterIP: None
定制alertmanager镜像#
alertmanager集群高可用采用statefulset方式部署,在实例启动时,需要在启动参数cluster.listen-address指定各peer的ip,可以在pod启动时通过变量传入,自定义启动脚本来解决 1.自定义启动脚本start.sh
$ cat start.sh
#!/bin/bash
IFS=',' read -r -a peer_ips <<< "${PEER_ADDRESS}"
str="--cluster.peer="
args=""
for ip in ${peer_ips[@]}; do
args=${args}${str}${ip}" "
done
/app/bin/alertmanager \
--config.file=/etc/config/alertmanager.yml \
--storage.path=/data \
--web.external-url=/ \
--cluster.listen-address=${NODE_NAME}:9094 \
$args
tail -f /app/bin/hold.txt
2.定制镜像
$ cat Dockerfile
FROM prom/alertmanager:v0.15.3 as alertmanager
FROM selfflying/centos7.2:latest
COPY start.sh /
RUN chmod +x /start.sh
ENTRYPOINT ["sh","/start.sh"]
$ docker build -t 192.168.1.50:5000/library/centos7.2_alertmanager:v0.15.3 .
$ docker push 192.168.1.50:5000/library/centos7.2_alertmanager:v0.15.3
创建statefulset#
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: alertmanager
namespace: kube-system
labels:
k8s-app: alertmanager
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v0.15.3
spec:
serviceName: "alertmanager"
podManagementPolicy: "Parallel"
replicas: 3
selector:
matchLabels:
k8s-app: alertmanager
version: v0.15.3
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.15.3
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
- effect: NoSchedule
key: node-role.kubernetes.io/master
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- alertmanager
topologyKey: "kubernetes.io/hostname"
priorityClassName: system-cluster-critical
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: prometheus-alertmanager
image: "192.168.1.50:5000/library/centos7.2_alertmanager:v0.15.3"
imagePullPolicy: "IfNotPresent"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: PEER_ADDRESS
value: "192.168.1.50:9094,192.168.1.51:9094,192.168.1.52:9094"
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
resources:
limits:
cpu: 1000m
memory: 500Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
volumeClaimTemplates:
- metadata:
name: storage-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "alertmanager-lpv"
resources:
requests:
storage: 20Gi
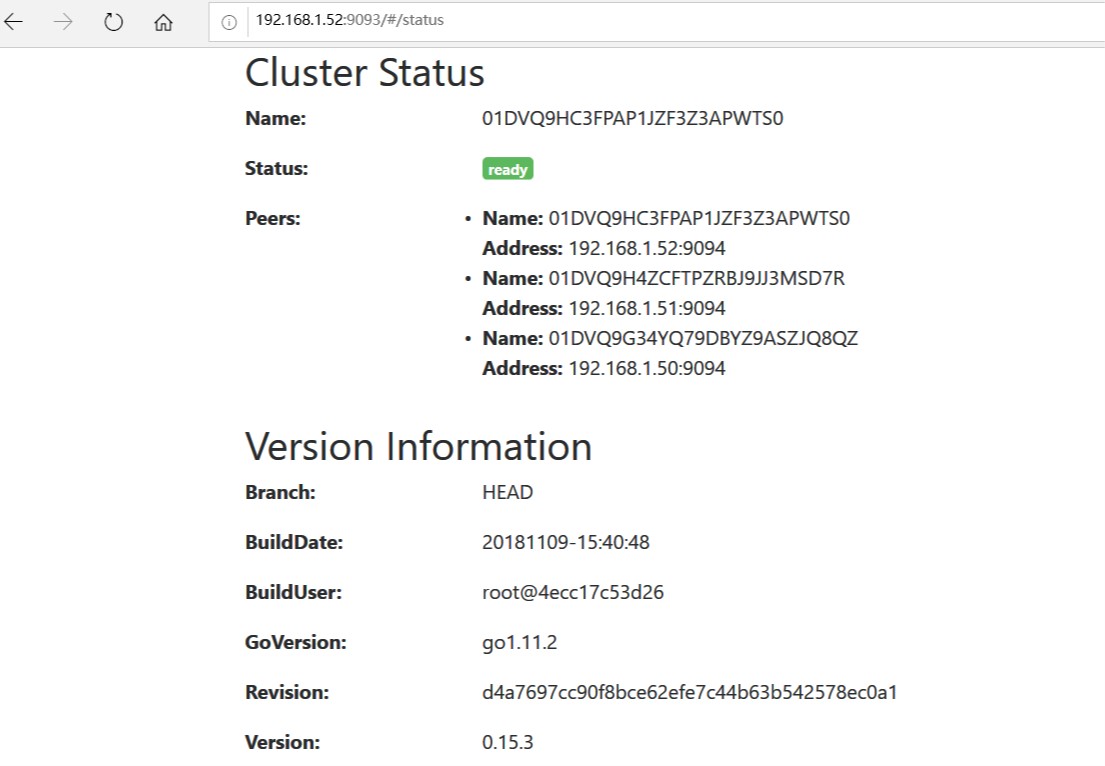
访问alertmanager web页面#
集群创建成功http://192.168.1.52:9093/#/statusAlertmanager
prometheus-federate配置告警规则#
修改prometheus-federate的configmap.yaml
#cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-federate-config
namespace: kube-system
data:
alertmanager_rules.yaml: |
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
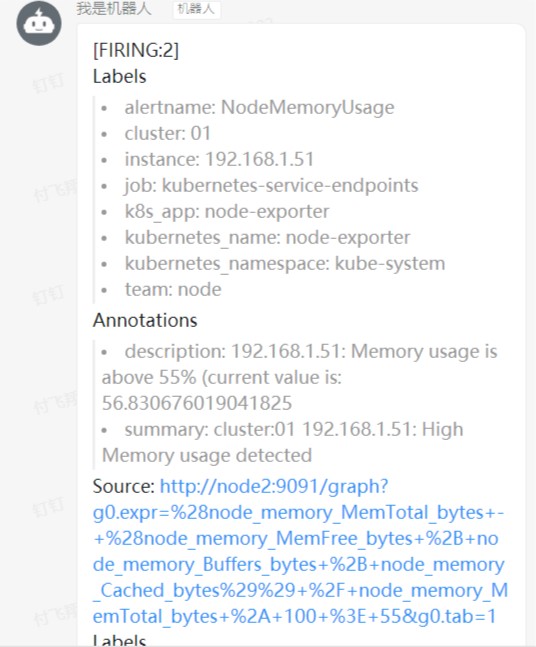
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes -(node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 55
for: 1m
labels:
team: node
annotations:
summary: "cluster:{{ $labels.cluster }} {{ $labels.instance }}: High Memory usage detected"
description: "{{ $labels.instance }}: Memory usage is above 55% (current value is: {{ $value }}"
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
#remote_write:
# - url: "http://29.20.18.160:9201/write"
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager-0.alertmanager:9093
- alertmanager-1.alertmanager:9093
- alertmanager-2.alertmanager:9093
rule_files:
- "/etc/prometheus/alertmanager_rules.yaml"
scrape_configs:
- job_name: 'federate'
scrape_interval: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"kubernetes.*"}'
- '{job="prometheus"}'
static_configs:
- targets:
- 'prometheus-0.prometheus:9090'
- 'prometheus-1.prometheus:9090'
从prometheus federate web 可以看到添加的两条告警规则
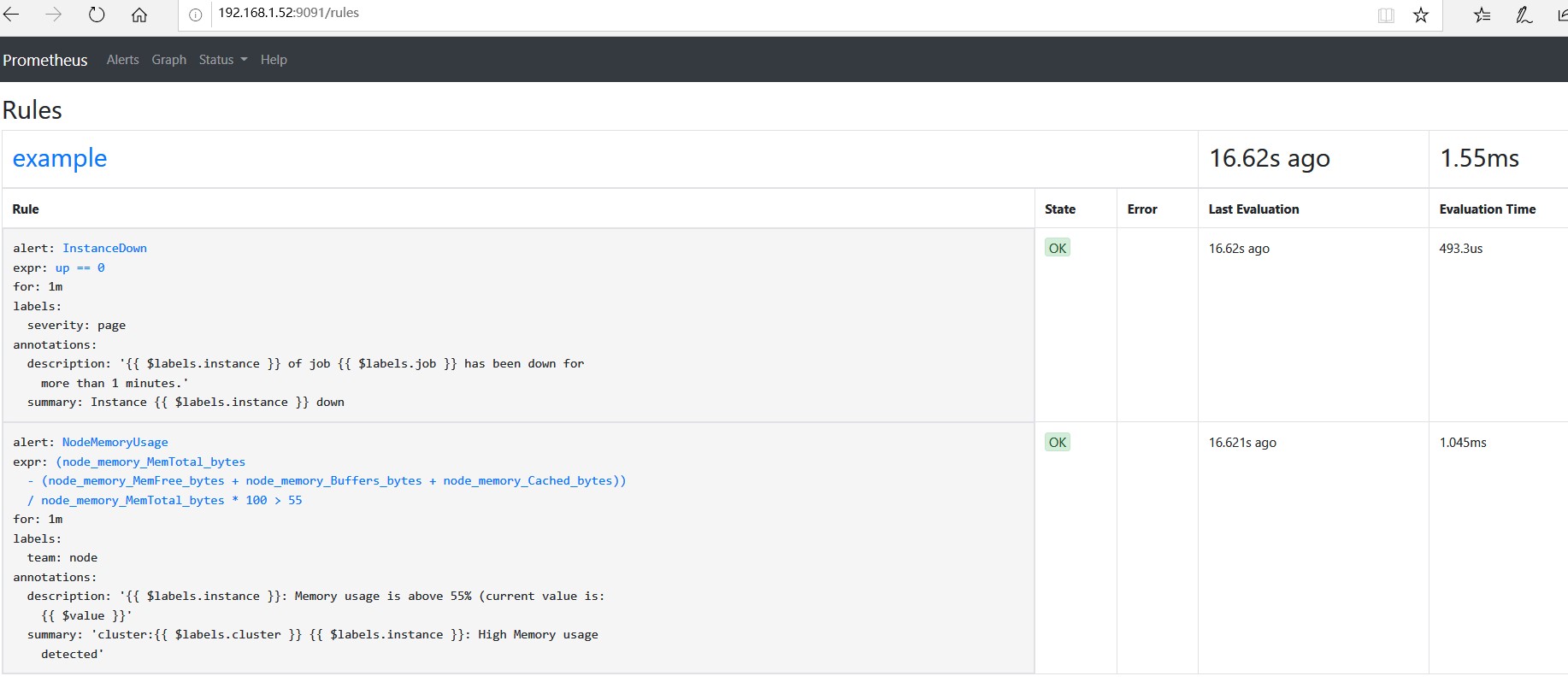
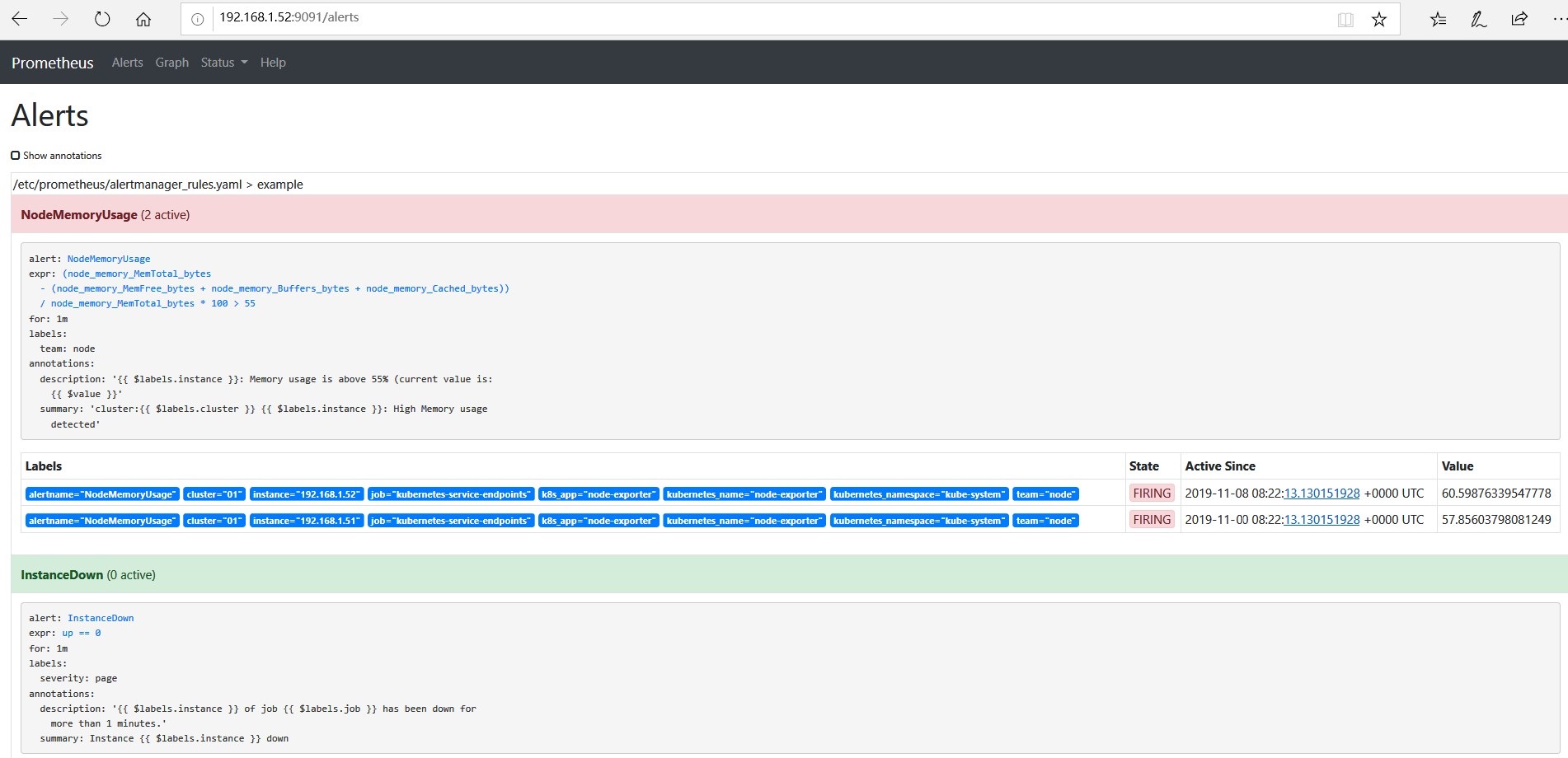
告警信息生命周期的3中状态
- inactive:表示当前报警信息即不是firing状态也不是pending状态
- pending:表示在设置的阈值时间范围内被激活的
- firing:表示超过设置的阈值时间被激活的
alertmanger web页面可以看到此告警,表示已成功推送
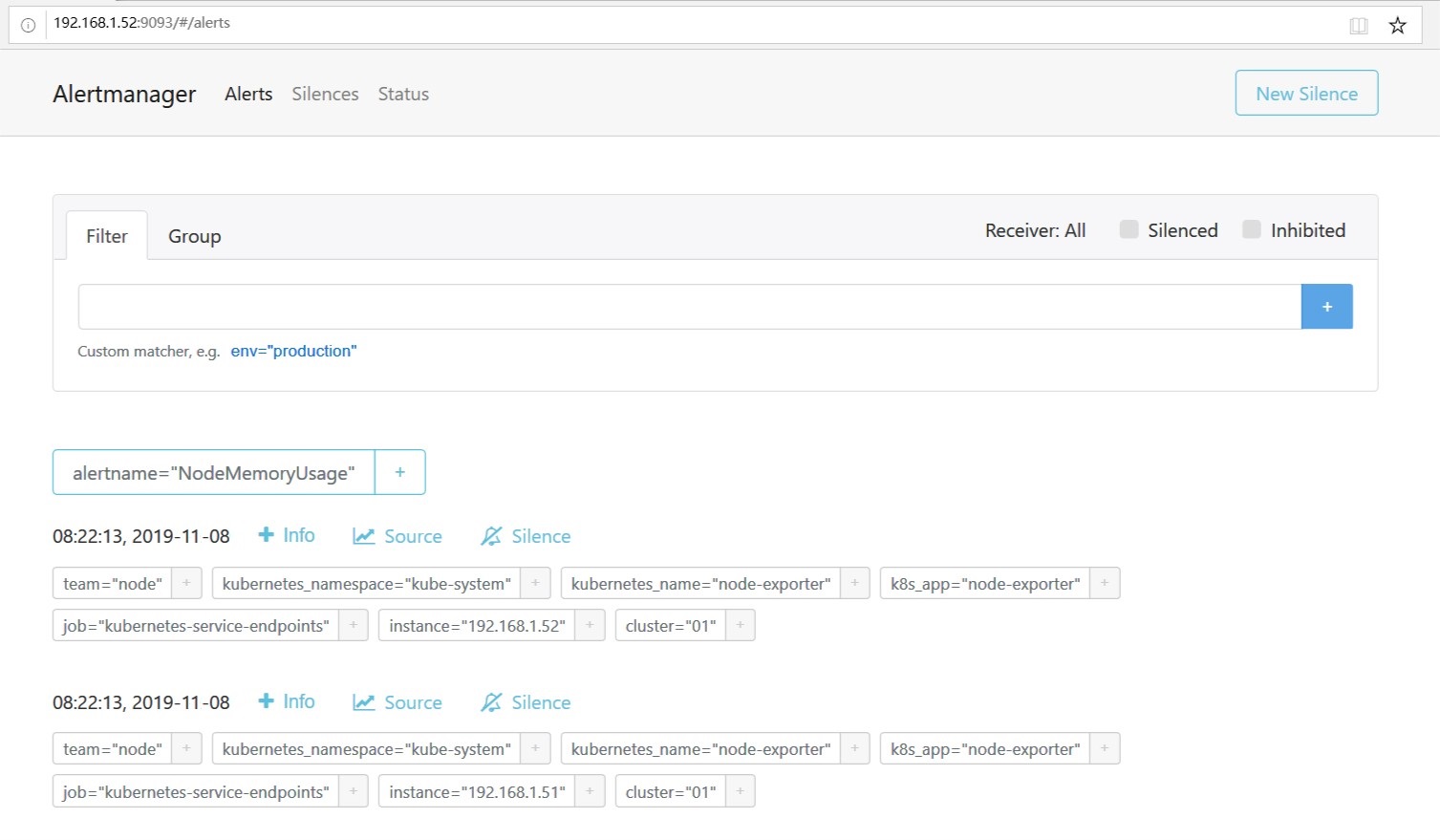
同时,钉钉群也收到了告警信息
高可用prometheus监控集群部署 - This article is part of a series.
Part 4: This Article
Related
高可用prometheus监控集群搭建(三)
·394 字·2 分钟
kubernetes
prometheus
高可用prometheus监控集群搭建(一)
·803 字·4 分钟
kubernetes
prometheus
高可用prometheus监控集群搭建(二)
·496 字·3 分钟
kubernetes
prometheus